义乌商城集团网站建设企业网站seo托管怎么做
1、Scrapy框架初识
2、Scrapy框架持久化存储(点击前往查阅)
3、Scrapy框架内置管道(点击前往查阅)
4、Scrapy框架中间件(点击前往查阅)

Scrapy 是一个开源的、基于Python的爬虫框架,它提供了强大而灵活的工具,用于快速、高效地提取信息。Scrapy包含了自动处理请求、处理Cookies、自动跟踪链接、下载中间件等功能。
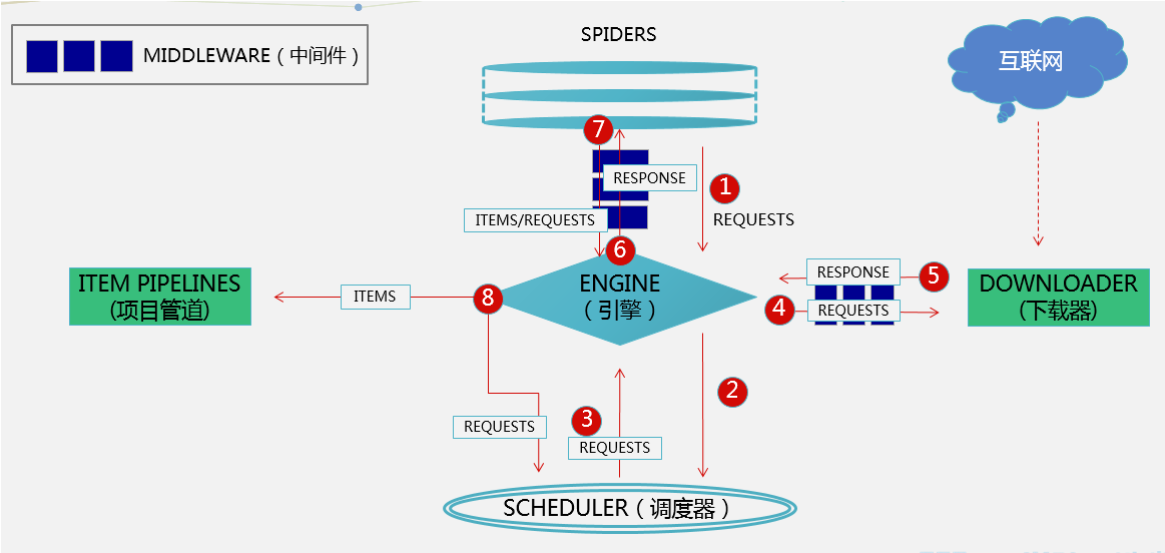
Scrapy框架的架构图(先学会再来看,就能看懂了!)
一、安装
在Pycharm终端中使用以下命令安装 Scrapy:
pip install scrapy
二、创建 Scrapy 项目
在Pycharm终端中使用以下命令创建一个 Scrapy 项目:
scrapy startproject project_name
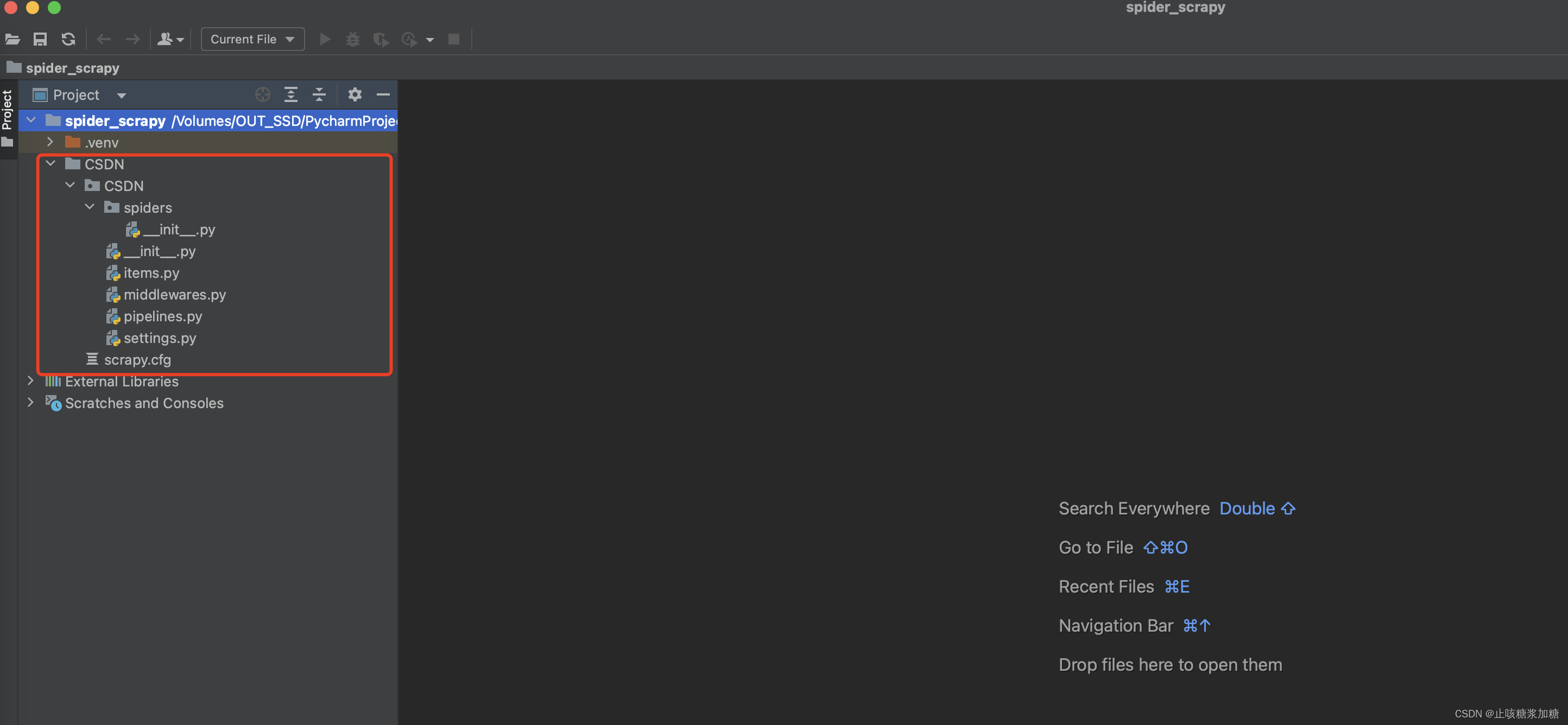
其中 project_name 是你文件夹的名字(文件名只能以字母开头,只能包含数字、字母、下划线),下面是创建好的目录结构(.venv 这个文件无视,这个是我配置的虚拟环境,这个地方不做多讲解,想了解点击这:虚拟环境讲解)。
三、创建爬虫项目
在Pycharm终端中使用以下命令创建一个 Scrapy 项目:
scrapy genspider spider_name example.com
命令讲解:
- spider_name:是你的爬虫文件名(名字不能和scrapy项目重复)
- example.com:初始设置的网址(这个随便填写,等下可以改的,可以设置www.xxx.com)
注意:需要先进入你创建的Scrapy项目中,例如:我这个文件名是:CSDN
对比下绿色横线的文件目录就发现不一样了。

⬇️⬇️⬇️执行的命令演示⬇️⬇️⬇️

3.1:创建好的目录结构

四、编写爬虫
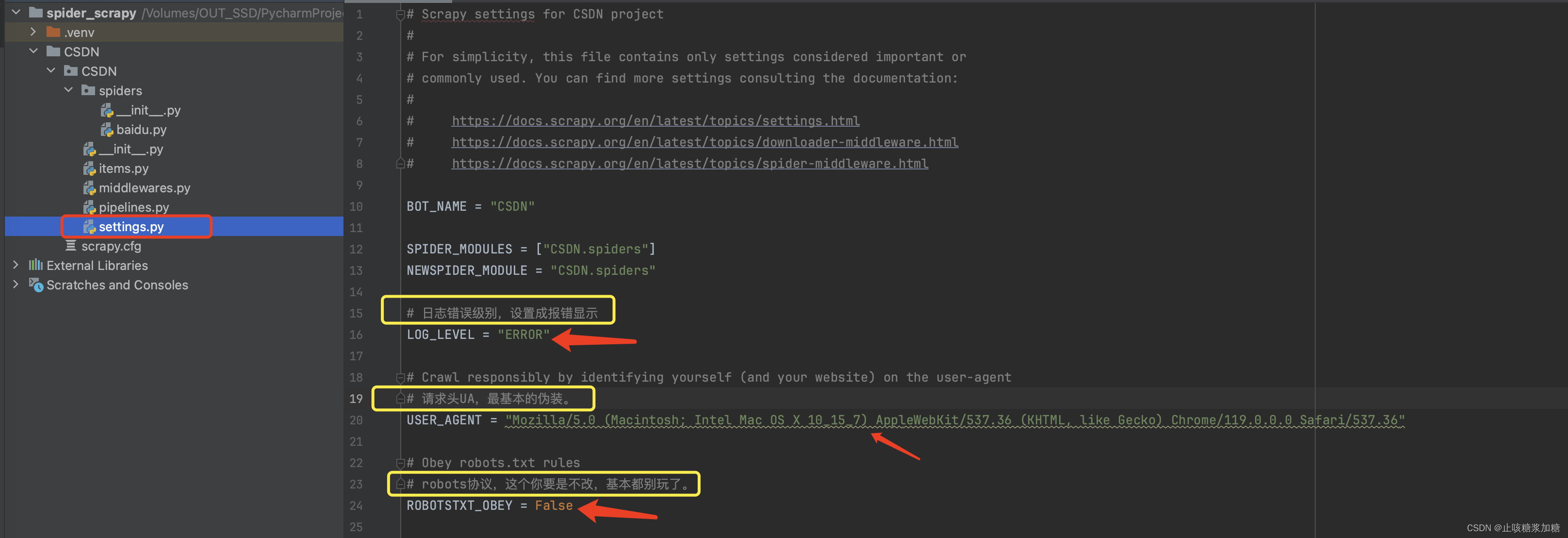
4.1:setting设置
设置 setting 中需要改动的地方(这个是基本的设置,其他的根据需要来开启)
4.2:代码初识
打开创建好的爬虫文件(baidu.py)进入编写我们的程序:
初始的是这样的:
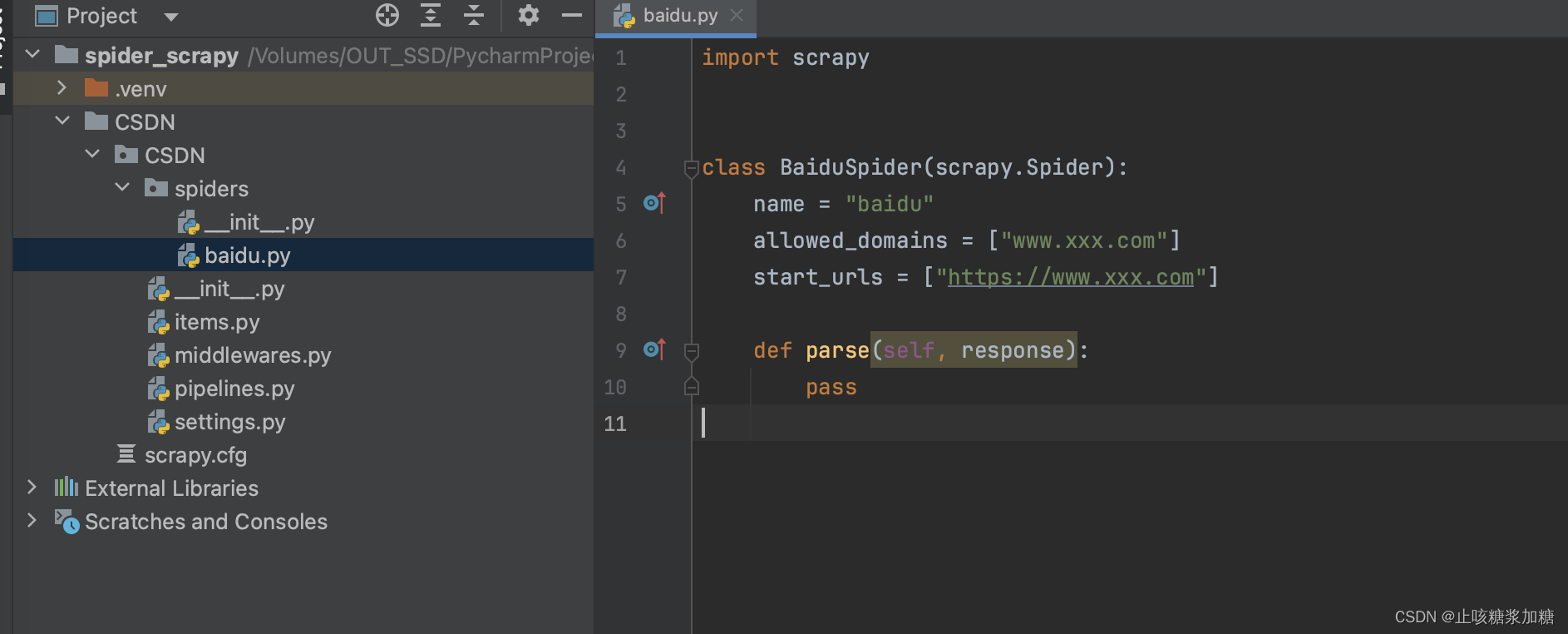
代码的含义: 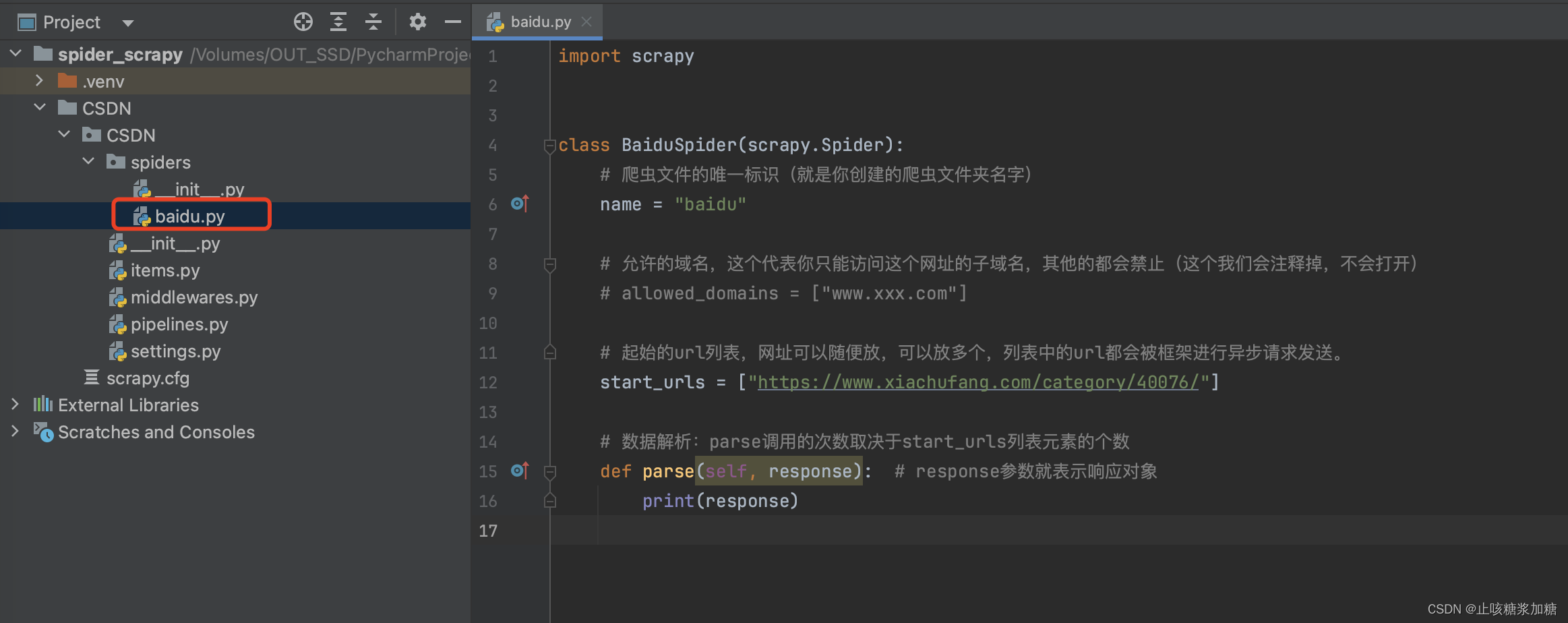
4.3:数据解析(parse函数)
演示网站:(不可干预人家网站的正常运行!!!)家常菜做法大全有图_家常菜菜谱大全做法_好吃的家常菜_下厨房【下厨房】家常菜栏目为您提供最新的家常菜做法大全、家常菜菜谱大全和步骤,让你也可以轻松做出好吃的家常菜![]() https://www.xiachufang.com/category/40076/
https://www.xiachufang.com/category/40076/
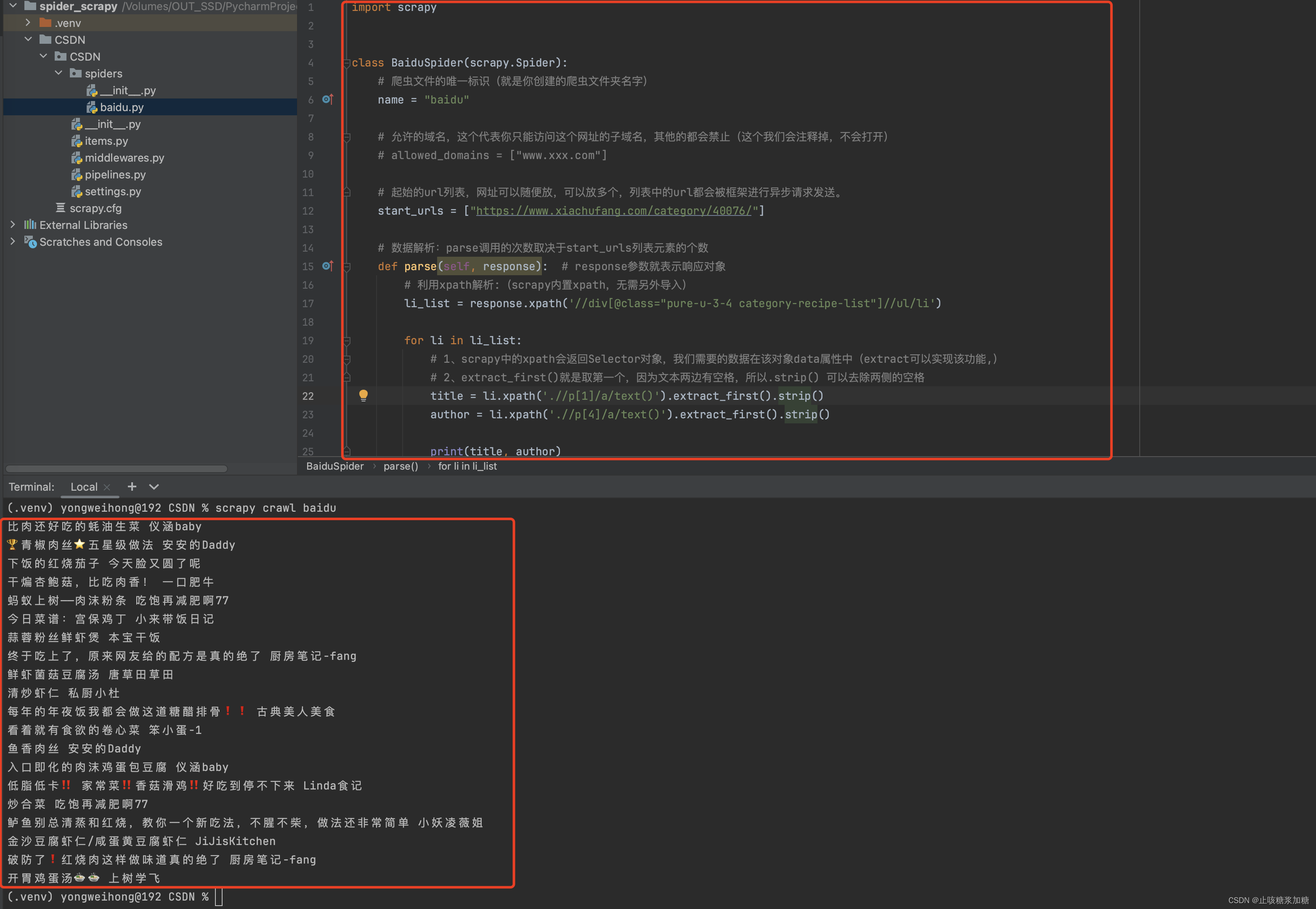
需求:第一页的所有的菜名和作者

最终代码:
import scrapyclass BaiduSpider(scrapy.Spider):# 爬虫文件的唯一标识(就是你创建的爬虫文件夹名字)name = "baidu"# 允许的域名,这个代表你只能访问这个网址的子域名,其他的都会禁止(这个我们会注释掉,不会打开)# allowed_domains = ["www.xxx.com"]# 起始的url列表,网址可以随便放,可以放多个,列表中的url都会被框架进行异步请求发送。start_urls = ["https://www.xiachufang.com/category/40076/"]# 数据解析:parse调用的次数取决于start_urls列表元素的个数def parse(self, response): # response参数就表示响应对象# 利用xpath解析:(scrapy内置xpath,无需另外导入)li_list = response.xpath('//div[@class="pure-u-3-4 category-recipe-list"]//ul/li')for li in li_list:# 1、scrapy中的xpath会返回Selector对象,我们需要的数据在该对象data属性中(extract可以实现该功能,)# 2、extract_first()就是取第一个,因为文本两边有空格,所以.strip() 可以去除两侧的空格title = li.xpath('.//p[1]/a/text()').extract_first().strip()author = li.xpath('.//p[4]/a/text()').extract_first().strip()print(title, author)
输出结果:
五、运行爬虫
使用以下命令运行你的 Scrapy 爬虫:
scrapy crawl myspider
命令讲解
- myspider:你的爬虫文件名字(例如我的是:baidu)