不用购买域名做网站seo搜索引擎优化工具
目录
前言
平台维度
docker运行状态
cAdvisor-日志采集者
Heapster-日志收集
metrics-server-出生决定成败
kube-state-metrics-不完美中的完美
应用维度
日志
部署方式
输出方式
工具选择
日志接入
监控
serviceMonitor
Annotation
Prometheus扩展性
Thanos
方案一:thanos sidecar + thanos query
方案二:thanos receive + thanos query
总结
前言
运维体系中的日志和监控是个频率很高的知识点,日志如何采集和收集?监控如何采集和收集?运行在容器云中的监控与云实例中的监控有什么本质区别?本篇将为大家解读这些概念并对当前主流工具进行简单介绍。
首先要强调的一点是,运行在容器云中业务的稳定性是由容器云平台稳定性和应用稳定性两部分决定的,而前者是公有云实例场景中不需要考虑的,也是容器云运维非常核心的一个模块。所以日志与监控也要按平台和应用两个维度来拆分。
平台维度
k8s是个很大的框架,对于它的监控也是个很复杂的问题,让我们从管理一个单独docker的视野开始,感受下平台监控体系是如何生长的。
docker运行状态
docker运行状态怎么知道?docker status命令可以知道容器运行的状态,但它的缺点太多了:只能手工敲命令,不能http协议,不能metric数据,总之不符合自动化管理的理念。
cAdvisor-日志采集者
为了解决docker status的缺陷,于是产生了cAdvisor。用工具替代手动,它可以采集容器状态和CPU等资源指标,核心分为machineInfo和containerInfo两个模块,从模块名称可以看出不仅可以采集容器的指标,还能采集宿主机的指标,在K8S中集成在Kubelet里作为默认启动项,每个node上运行一个cAdvisor。
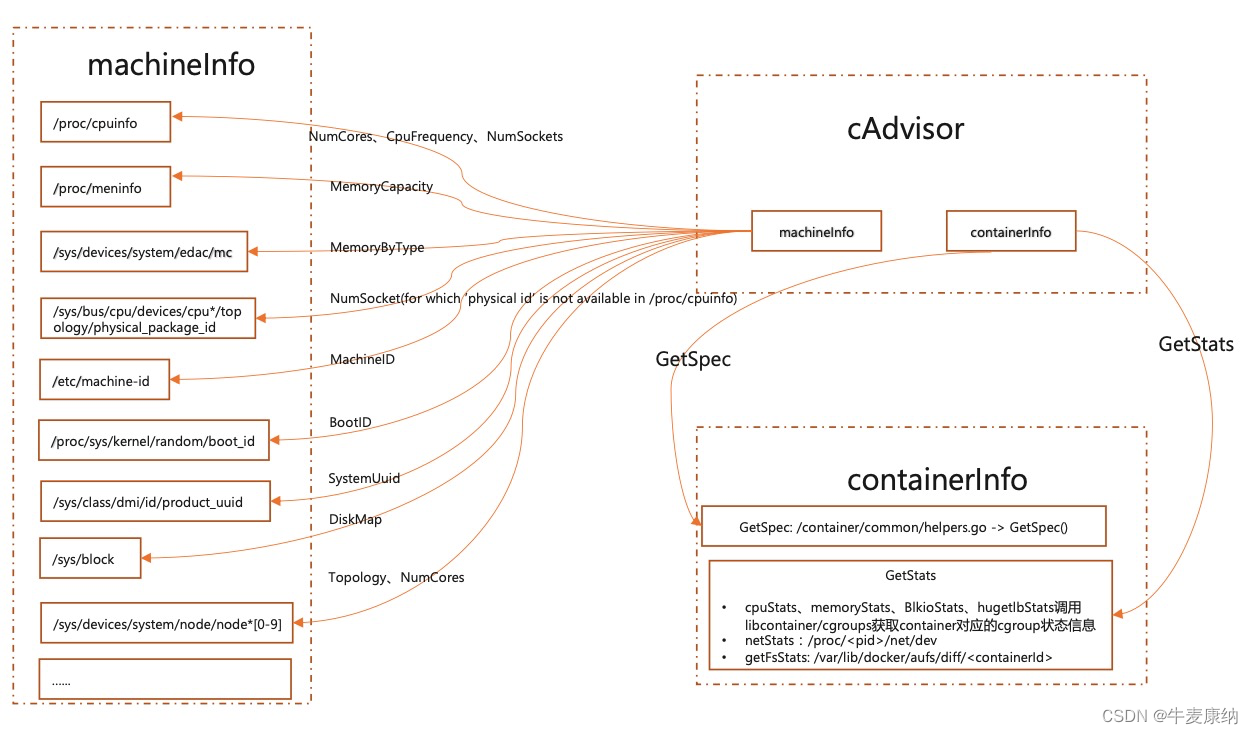
cAdvisor帮我们解决了从手动到自动的过程,BUT,每个节点的cAdvisor指标需要单独采集,不适合大规模集群。
Heapster-日志收集
cAdvisor虽然能提供有用的平台数据,但其分散在每个node上,Heapster负责把它们收集后统一处理。Heapster的本质就是一个收集者,将每个Node上的cAdvisor的数据进行汇总,然后导到第三方工具。
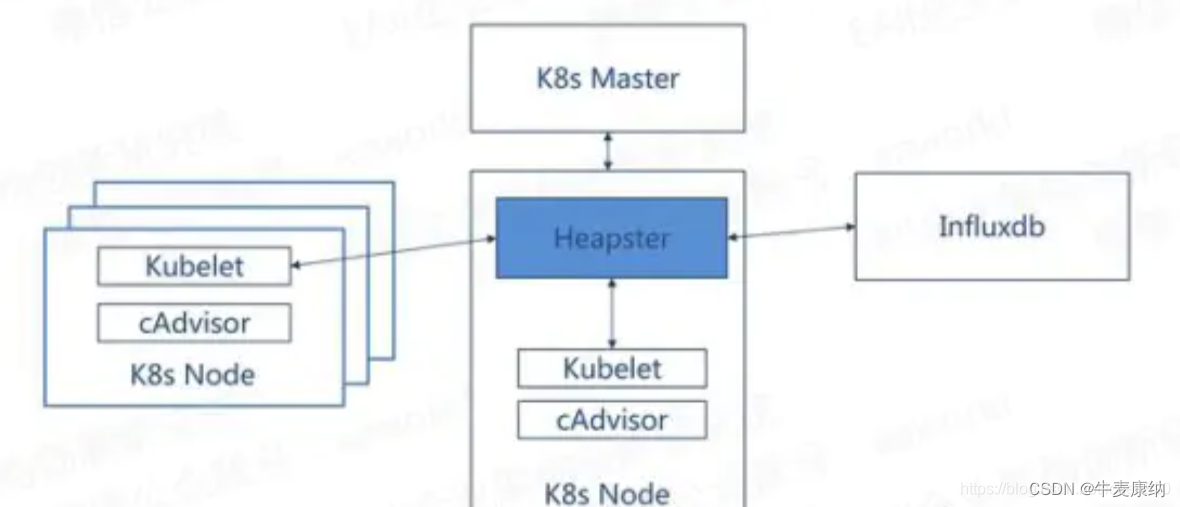
到此为止我们解决了监控的问题,但还没有解决告警问题,那就是Prometheus的天下了,但Prometheus对监控数据格式有要求,必须按照metric的格式来,很遗憾Heapster不支持!
metrics-server-出生决定成败
为了稳固Prometheus(云原生监控一哥)的地位,Heapster被废弃,metrics-server上位。可以说metrics-server要干的事跟Heapster要干的事基本是一样的,但metrics-server通过 kube-apiserver ( /apis/metrics.k8s.io/)可以将metric数据暴漏出来。
整个调用链是这样的:Prometheus->metrics-server->kubelet->cAdvisor
kube-state-metrics-不完美中的完美
metrics-server并不是完美的,有些k8s特定的场景它的监控指标并不能支持,例如:pod有没有重启过?伸缩有没有成功?所以新的帮手出现了kube-state-metrics
metric-server和kube-state-metrics是共生的关系,它们侧重点不一样。metric-server关注的是k8s的资源监控指标,kube-state-metrics关注于获取 k8s 各种资源的最新状态。
metric-server仅仅是获取、格式化现有数据,写入特定的存储,实质上是一个监控系统。而kube-state-metrics是将k8s的运行状况在内存中做了个快照,并且获取新的指标,但他没有能力导出这些指标
应用维度
日志
部署方式
应用日志采集在设计上分为DaemonSet和SideCar两种方式,前者是运行在node上,后者是运行在pod上,那我们该如何取舍呢?
DaemonSet在稳定性、侵入性、资源占用方面有优势,但隔离性、性能方面SideCar方式更好。我们实践中会优先使用DaemonSet方式采集日志。如果某个服务日志量较大、吞吐量较高,可以考虑为该服务的Pod配置Sidecar方式采集日志。
输出方式
应用日志的输出方式分为stdout和文件两种方式,云原生12要素主推的是stdout,但实际情况是做不到!一方面需要研发团队愿意陪你改造,另一方面确实有按场景输出到不同文件的需求。
工具选择
日志收集从古至今出现了不下于5种主流的角色(loggie、Filebeat、Fluentd、Logstash、Flume),我们该如何取舍呢?
结论1:工具没有好坏,只有是否合适。结论2:我们用的是loggie。出于性能上的考虑,首先淘汰掉Logstash和Flume;处于输出到文件的考虑,又淘汰掉Filebeat和Fluentd,所以留给我们的只有loggie了。
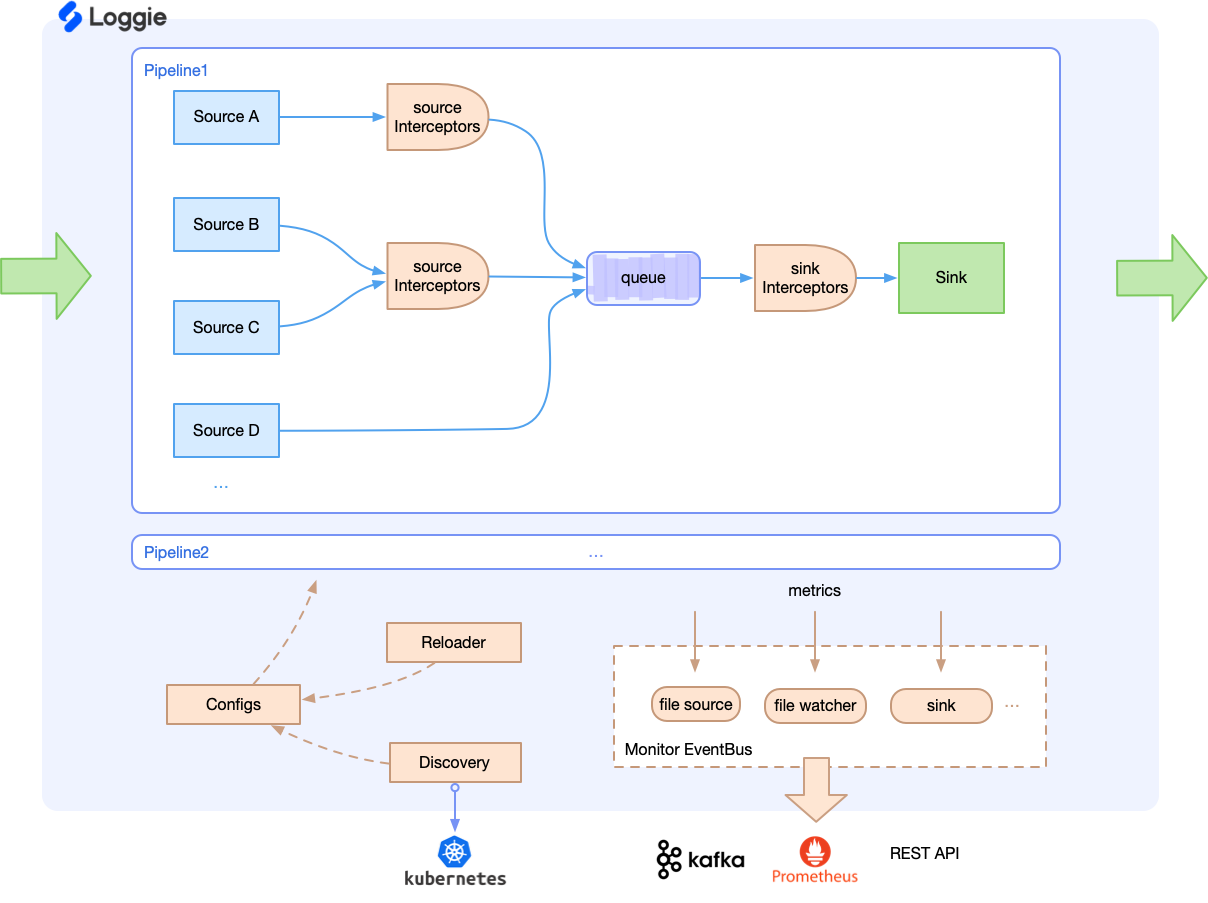
日志接入
容器云黑科技的接入基本都是通过CRD,loggie也是这样实现的。定义了一种叫LogConfig的资源,在它的manifest中通过spec.selector属性显式的定义了满足什么label的pod需要走什么样的pipeline。
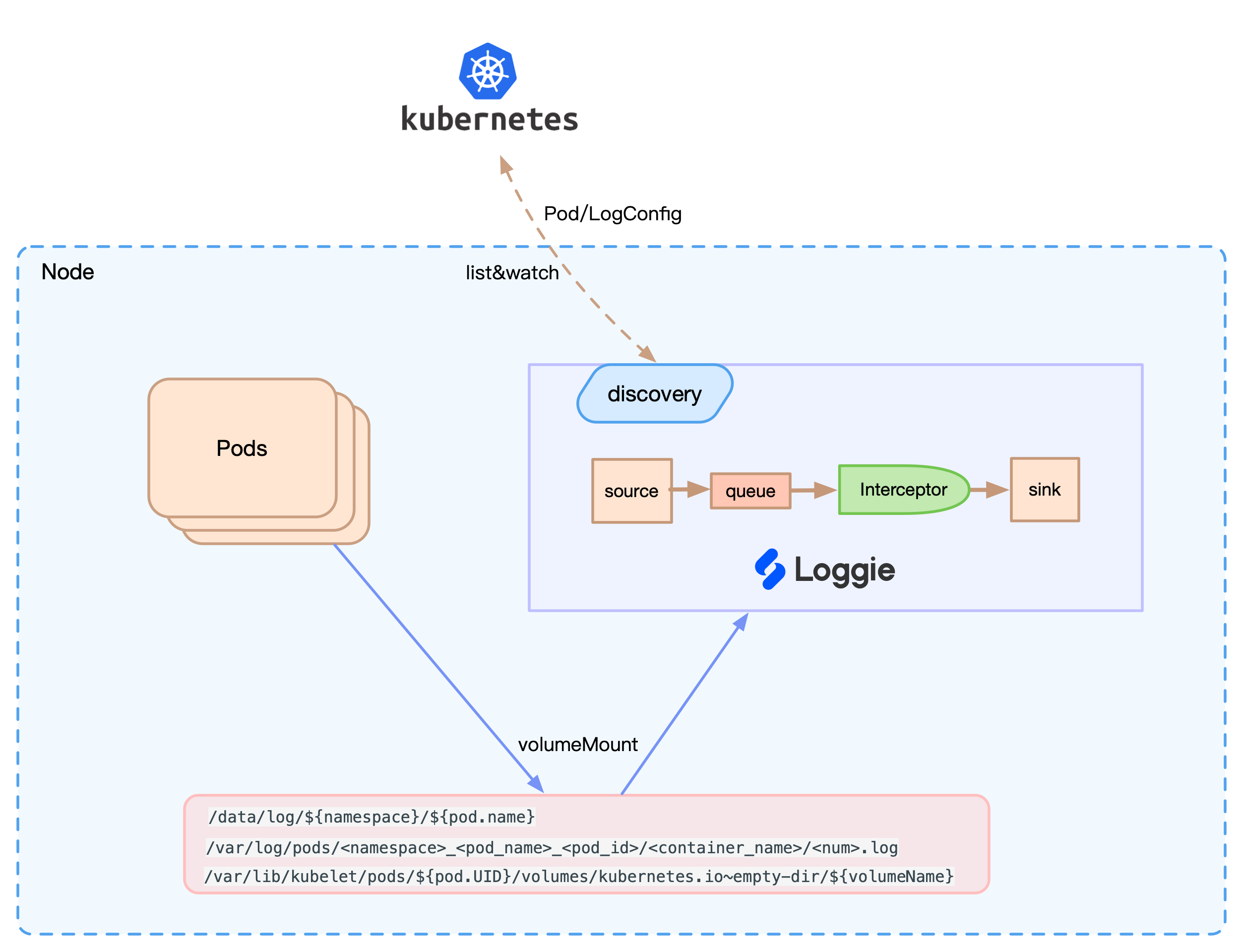
监控
应用的监控就是面向服务的监控,k8s中的服务就是service,怎么能知道哪些service需要被Prometheus监控?监控哪个入口?service中动态的pod如何自动注册到Prometheus中来?这一些列负载并且有关联的信息如何维护和管理?答案还是CRD,定义了一种叫serviceMonitor的资源
serviceMonitor
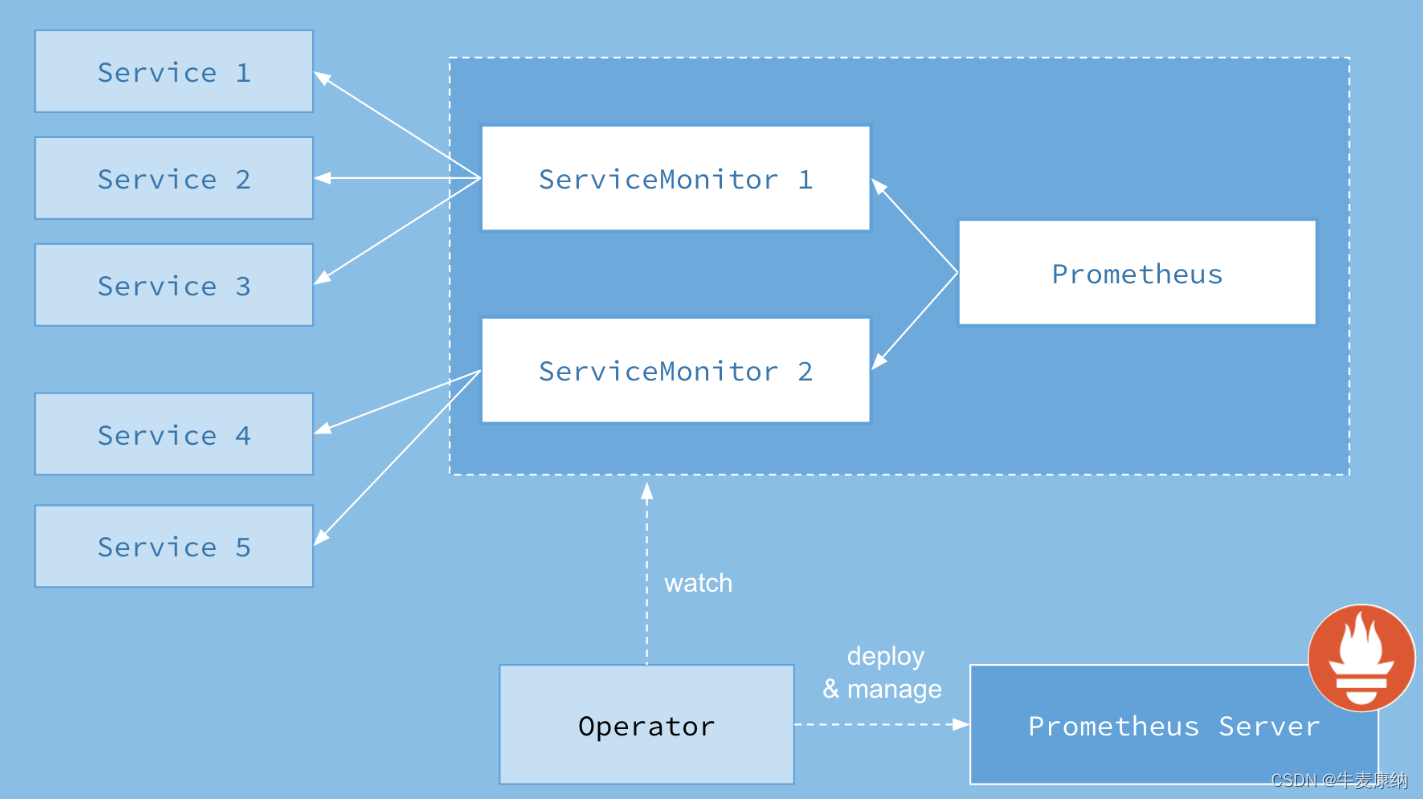
这里细节比较多,展开来解释下,首先定义一个serviceMonitor,里面描述了满足什么条件的pod会去如何与Prometheus交互
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:labels:Service: demo-exportername: demo-exporternamespace: monitoring
spec:endpoints:## 与Prometheus交互的间隔- interval: 60s## 获取metrics数据的端口,匹配的service中定义的端口名称port: demo-exporter-port## 获取metrics数据的pathpath: /metricsrelabelings:## 数据在Prometheus中打什么样的标签- sourceLabels: [__meta_kubernetes_pod_label_Cluster]targetLabel: Cluster- sourceLabels: [__meta_kubernetes_pod_label_Service]targetLabel: ServicenamespaceSelector:## 生效的命名空间列表matchNames:- prod- gray- canaryselector:matchLabels:## 生效pod的条件openMonitor: "on"service中打开该开关即可
---
apiVersion: v1
kind: Service
metadata:name: foo-web-prodlabels:Cluster: fooService: foo-webopenMonitor: "on"namespace: prod
spec:clusterIP: Noneselector:CPX: prodService: foo-webports:- port: 80name: httptargetPort: 80- port: 8088name: demo-exporter-porttargetPort: 8088serviceMonitor的方式用起来还是不够爽,有没有更简洁的接入方式呢?有,annotation!
Annotation
设计思路是,我们不去专门为每个service提前定义描述文件,而是让它们自己配置要怎么加入Prometheus,例如
spec:template:metadata:annotations:prometheus.io/path: /stats/prometheus #指定pathprometheus.io/port: "8088" #指定端口prometheus.io/scrape: "true" #启用prometheus.io这种设计需要改造两个地方,一个是自动发现,配置了annotation的就可以接入;一个是标签,可以保持pod自身的标签注入到Prometheus中。
参考文章:Prometheus Operator高级配置 · 从 Docker 到 Kubernetes 进阶手册
这种设计思路虽然用起来贼爽,但也有缺陷,如果需要监控多个端口还得另想办法,serviceMonitor就不存在这个问题,它是支持多端口的,endpoints配置是个列表。
Prometheus扩展性
从前面内容看得出无论是平台监控还是应用监控都离Prometheus,但是咱这个云原生一哥也有他自身的缺陷,那就是扩展性。Prometheus虽然性能强劲,但是从设计出就是个单机产品,算力、存储、网络吞吐都会成为压死骆驼的最后一根稻草,在互联网级别的监控体系中需要“分布式”Prometheus才能扛得住生产的压力。
Thanos
为了解决Prometheus单机瓶颈,Thanos横空出世。它也有两种落地方案,各有优劣。
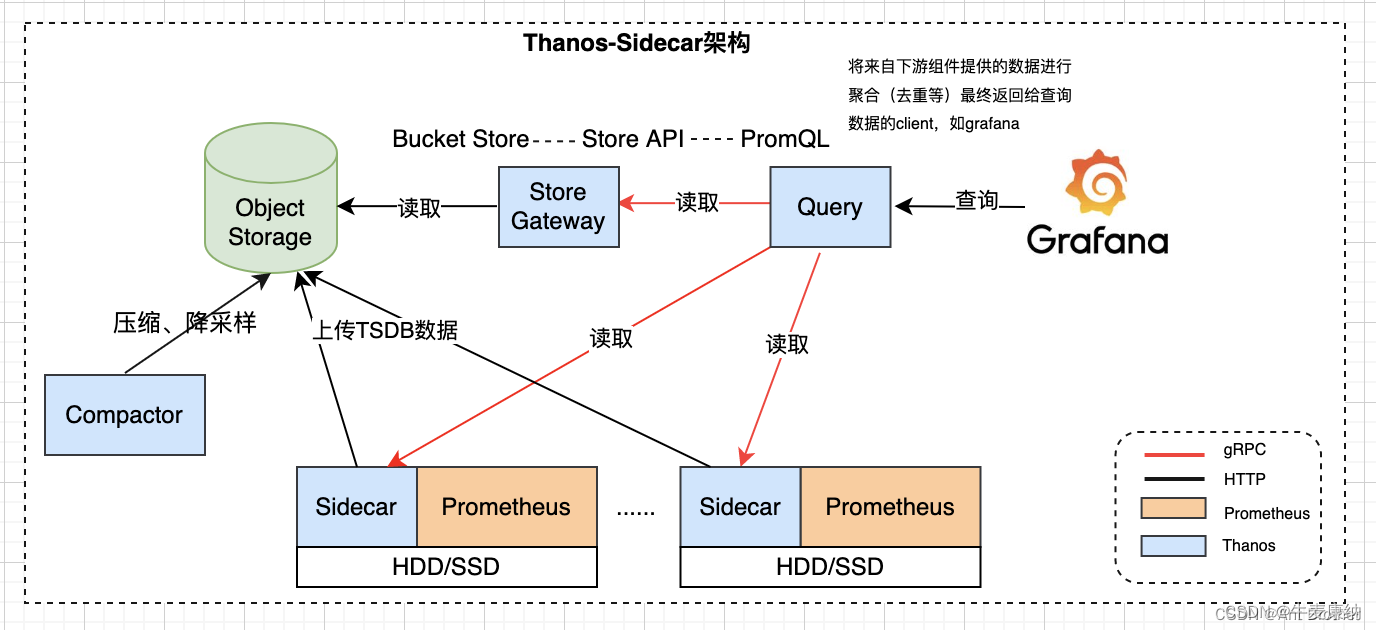
方案一:thanos sidecar + thanos query
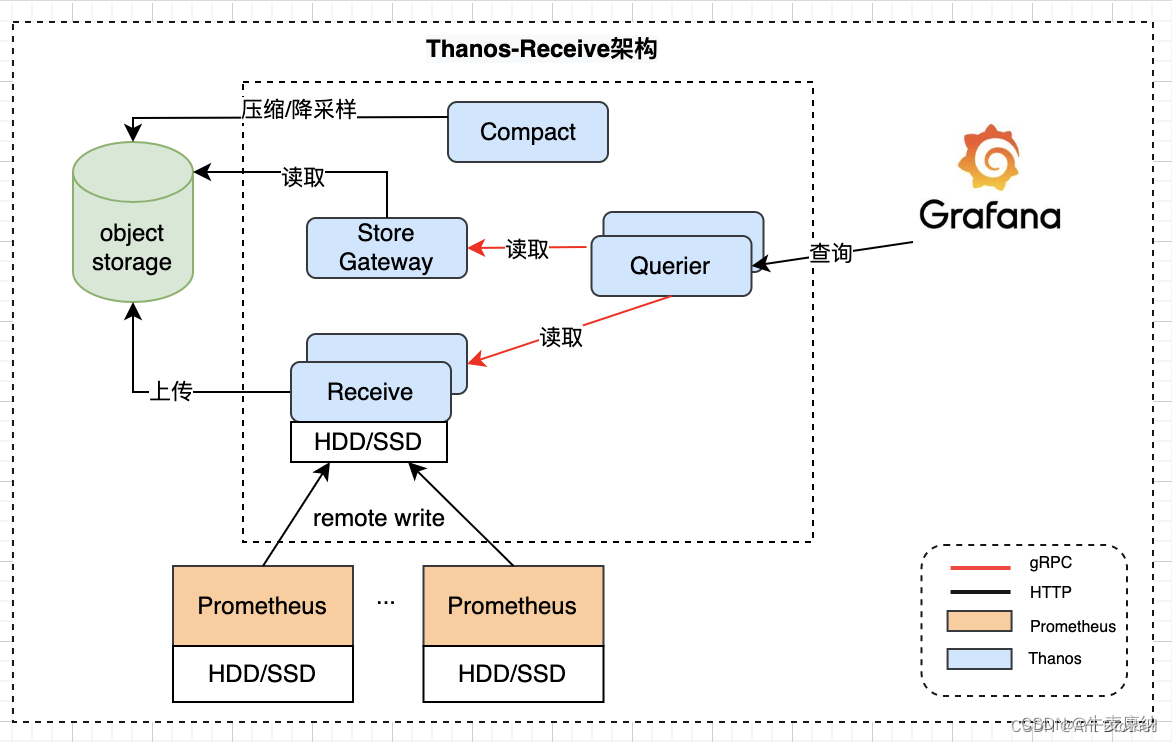
方案二:thanos receive + thanos query
sidecar方案优点:落地简单,只需要引入sidecar就好;
sidecar方案缺点:查询时Query效率不会太快,Prometheus如果挂了可能会丢失近期数据。
receive方案优点:结构清晰,Prometheus无状态,挂了不会丢数据,Query效率比sidecar方案高且可扩展。
receive方案缺点:需要新增和维护一套分布式存储,Prometheus远程写带来的延时对使用有多大影响也需要评估。
总结
学习技术并不只是学会一个工具怎么用,而是要学会一个工具是怎么来的,它的前世今生和这个领域从古至今的历史。一个工具势必是为了解决某个问题而被发明的,但它很可能又会在解决旧问题时引入新的缺陷。工具没有银弹,方案设计就是根据自己场景选择优点忍受缺点的过程。