百度站长工具域名查询百度站长统计
网页分析
首先打开中国福彩网,点击双色球,选择往期开奖栏目
进入栏目后,选定往期的奖金数目作为我们想要爬取的目标内容

明确目标后,开始寻找数据所在的位置
鼠标右击页面,打开网页源代码,在源代码中搜索是否存在奖金金额数目

搜索过后,发现这个金额数据没有在网页的源代码中,所以想到用抓包的方式来尝试获取这些金额数据
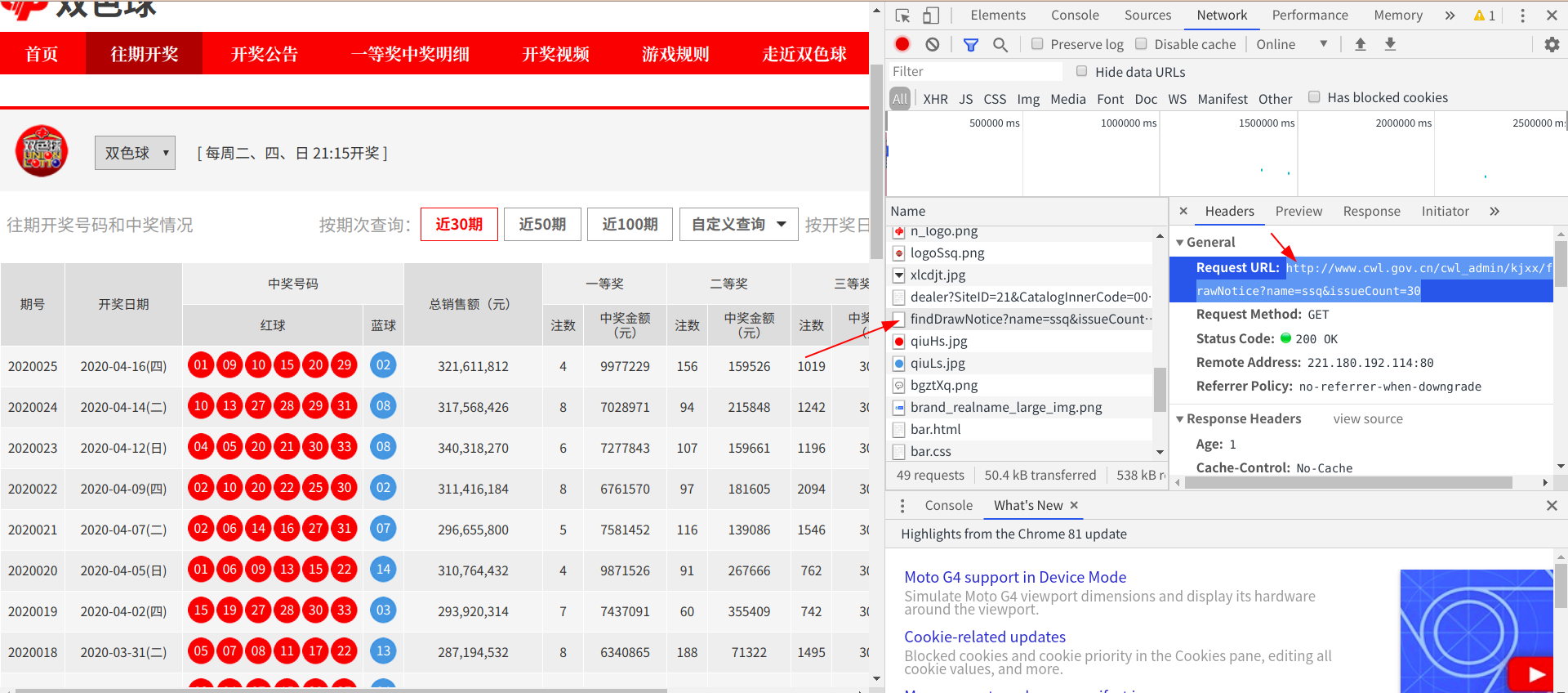
右击检查,选择network选项卡,按下ctrl+r键刷新界面,开始捕捉数据包
在过滤掉一些png、jpg的数据包之后,我们锁定了一个以findDrawNotice开头的数据包,打开观察数据包的内容,发现这个正是我们想要抓取的数据包
现在已经找到了想要抓包的内容,现在可以开始着手写代码了
数据提取
我们分析过网页之后,选定了要抓取的数据包,开始使用requests请求来获取数据
url = 'http://www.cwl.gov.cn/cwl_admin/kjxx/findDrawNotice?name=ssq&issueCount=30'
headers = {"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36","Referer":"http://www.cwl.gov.cn/kjxx/ssq/"}
response = requests.get(url,headers=headers).text这个网页可能会有一个小的反爬措施,于是我们就在headers中加入user-agent和referer两个头信息
我们使用print语句来打印一下response的内容

print之后会发现这个内容是以字符串的格式打印出来的,如果我们想从中提取数据,则必须将它转换成字典的格式
data_json = json.loads(response) #将数据转换为json格式将数据转换之后,我们就可以使用键值对的方式来提取我们想要的数据了
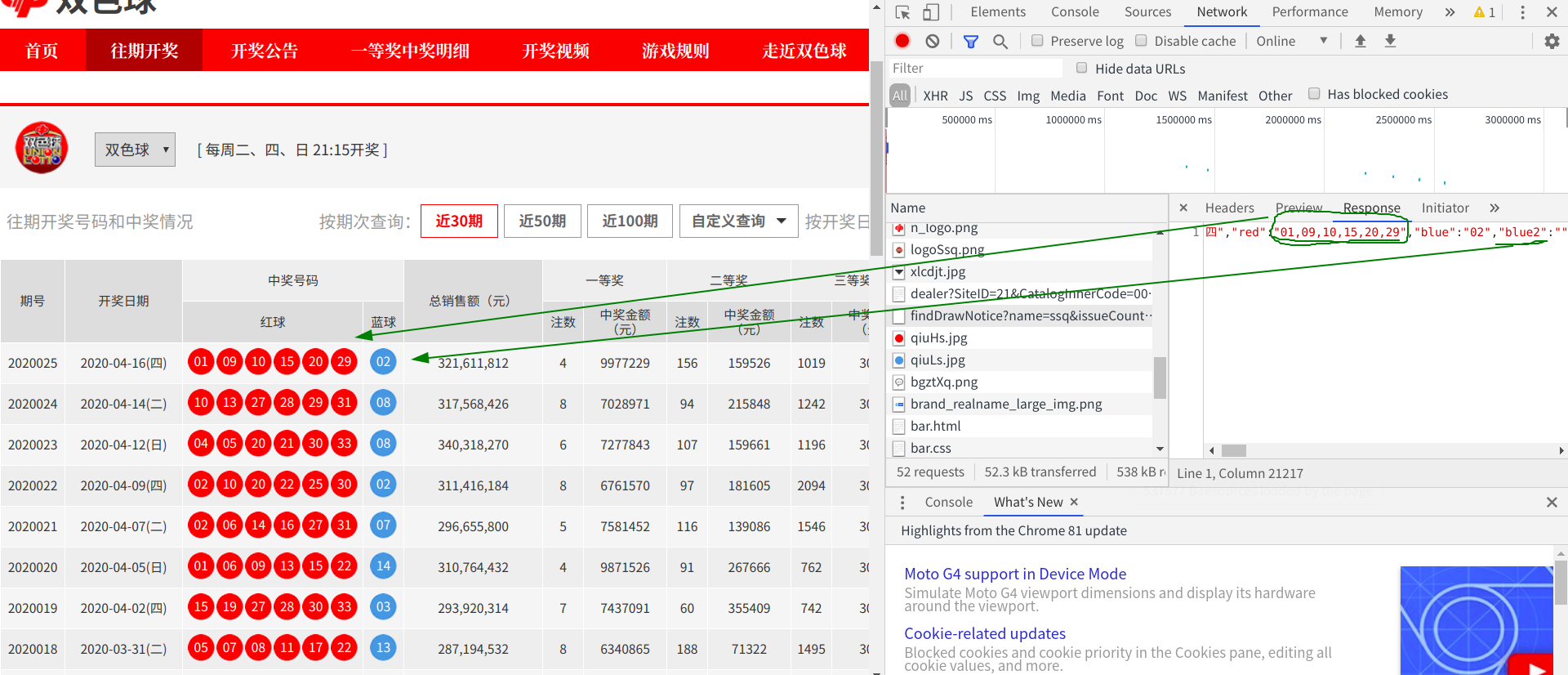
datas = data_json["result"]
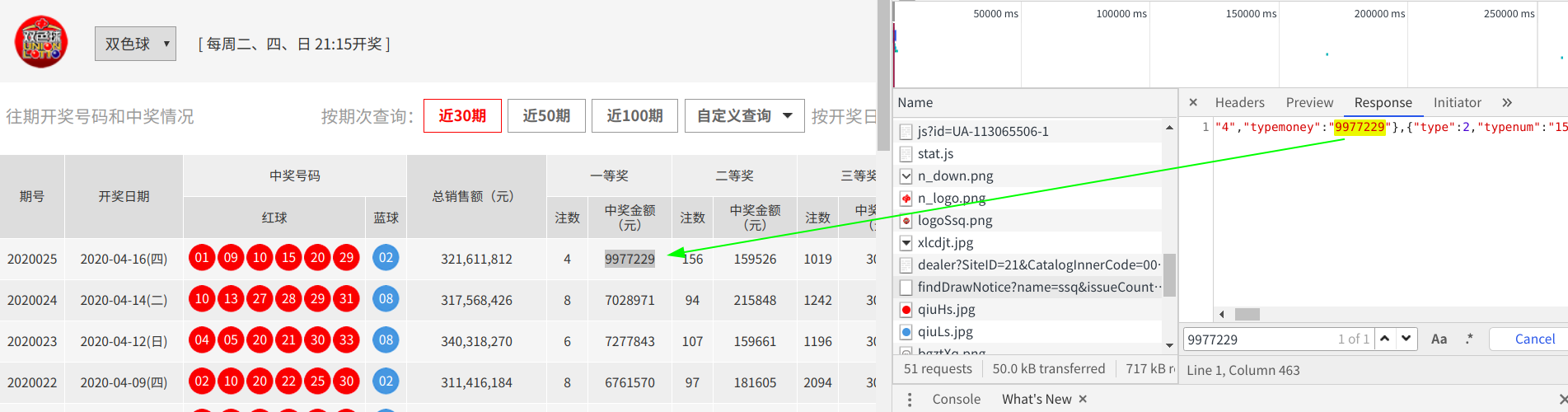
for data in datas:prizegrades = data["prizegrades"] #包含中奖金额的字典提取for item in prizegrades:print(item)typemoney = item['typemoney'] #中奖金额提取print(typemoney)这里我们尝试着逐层提取彩票的奖金信息,提取到最近的一层时,将数据打印出来分析数据
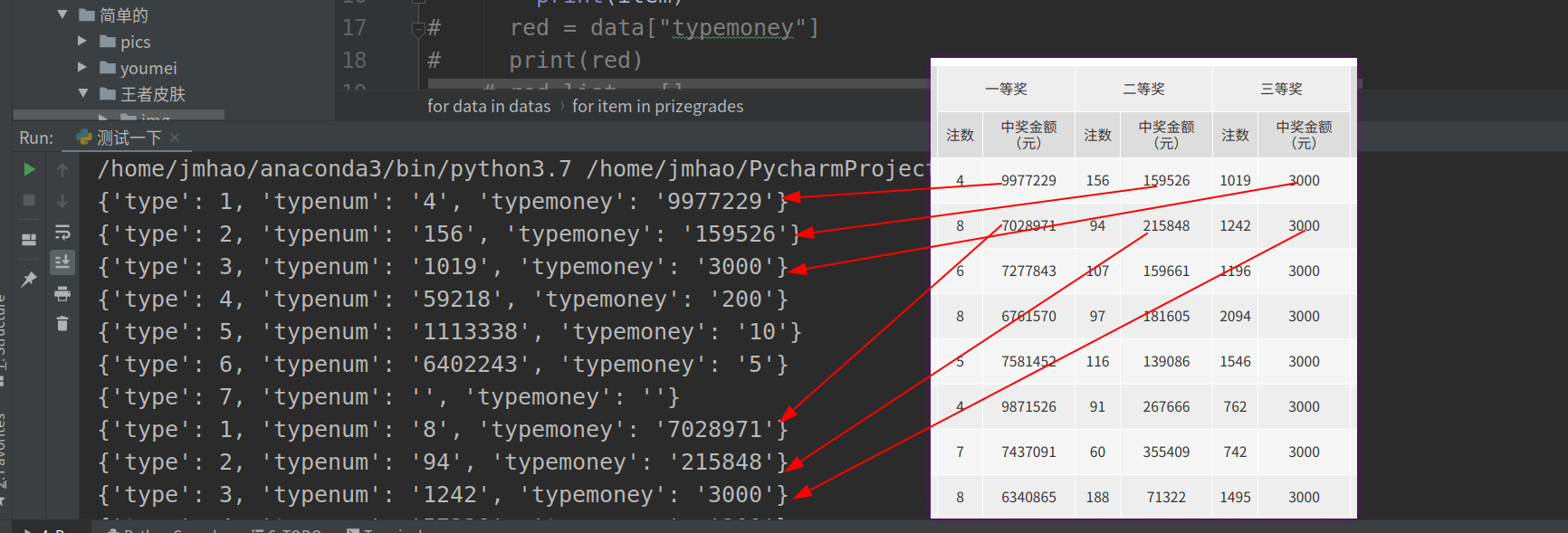
可以看到前三个和我们想要提取的数据内容是一致的,这些type后面的数字指的是奖金的等级,就是说对应到的号码是多少就是几等奖
到此为止,我们已经将需要获取的中奖金额提取出来了
转换数据
等我们看到这些数据的时候,虽然看到的是数字形式,但是他的数据类型确是字符形,通过此前对pygal模块的了解,我们知道这个模块只可以将整形的数字转换成图表格式。
所以我们需要做的就是将每一个数字提取出来,并且转换成整形存入到列表中
由于我们想要提取的只是一等奖的奖金金额(因为二、三等奖的金额远小于一等奖,不适合在图表中观察),所以这里我加上了一个if语句判断
money_list = [] #创建空列表
for data in datas:prizegrades = data["prizegrades"]for item in prizegrades:type_num = item['type']typemoney = item['typemoney']if type_num == 1: #判断奖金等级是否为1money_list.append(int(typemoney))但是我在运行这段代码的时候会提示错误,经过我的一番疯狂分析(百度求助),发现出错的原因是在提取奖金的时候会出现下划线和空字符串的干扰,而int转换数据类型则只能装换纯数字组成的字符串,所以转换的过程中会报错。但是这并不是一个大问题,我们只需要写一个if语句来跳过非法字符串就可以解决了,下面是正确的代码:
money_list = [] #创建空列表
for data in datas:prizegrades = data["prizegrades"]for item in prizegrades:typemoney = item['typemoney']if type_num == 1: #判断奖金等级是否为1if typemoney == "": #忽略空字符passelif typemoney == "_": #忽略下划线passelse: #将其他的可用数字放入列表money_list.append(int(typemoney))
print(money_list)观察输出:

将数据转换成图表
#设置图表样式为柱状图
view = pygal.Bar()
#图表名
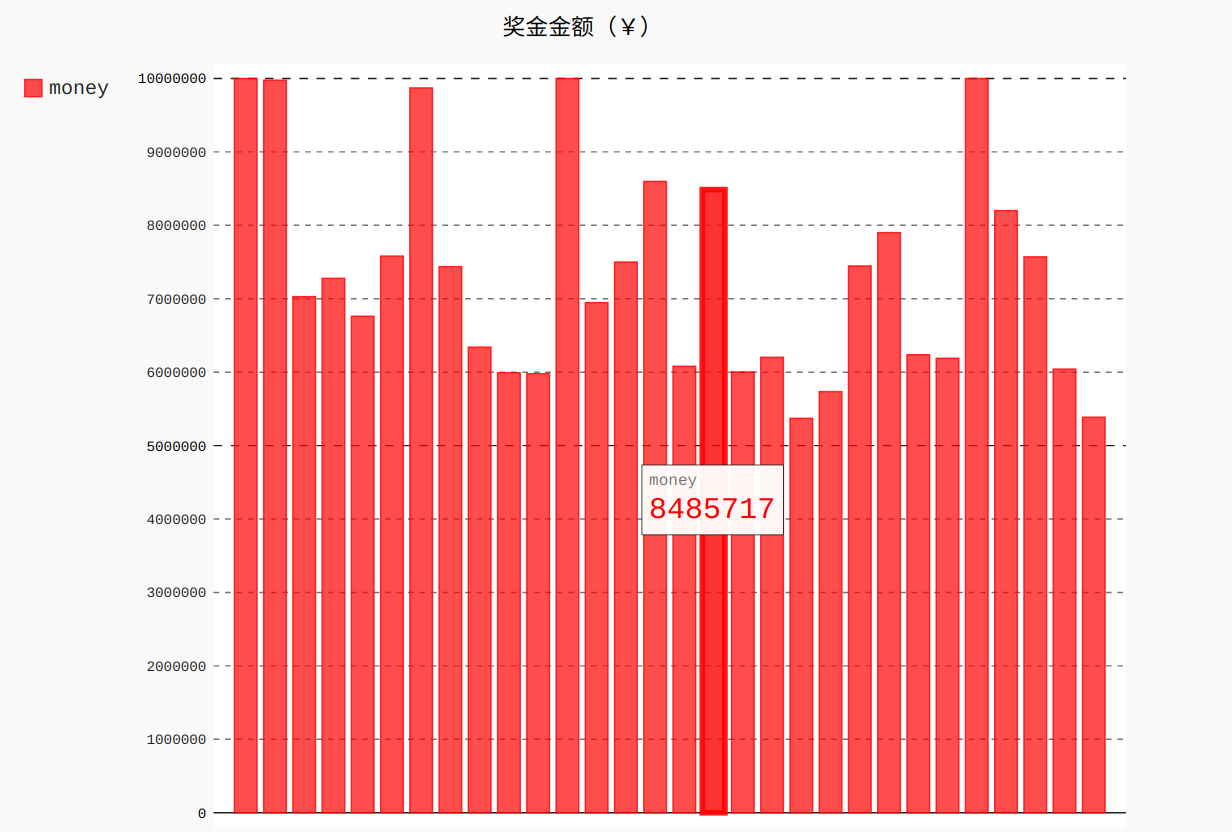
view.title = '奖金金额(¥)'
#将数据填入图表
view.add('money',money_list)
#在浏览器中显示图表
view.render_in_browser()完整代码
import json
import pygalurl = 'http://www.cwl.gov.cn/cwl_admin/kjxx/findDrawNotice?name=ssq&issueCount=30'
headers = {"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36","Referer":"http://www.cwl.gov.cn/kjxx/ssq/"}
response = requests.get(url,headers=headers).text
data_json = json.loads(response)
datas = data_json["result"]
money_list = [] #创建空列表
for data in datas:prizegrades = data["prizegrades"]for item in prizegrades:type_num = item['type']typemoney = item['typemoney']if type_num == 1: #判断奖金等级是否为1if typemoney == "": #忽略空字符passelif typemoney == "_": #忽略下划线passelse: #将其他的可用数字放入列表money_list.append(int(typemoney))#设置图表样式为柱状图
view = pygal.Bar()
#图表名
view.title = '奖金金额(¥)'
#将数据填入图表
view.add('money',money_list)
#在浏览器中显示图表
view.render_in_browser()实现结果