建设无障碍网站如何自创网站
文本上传构建向量库后台库的内容
调用上传文件接口先上传文件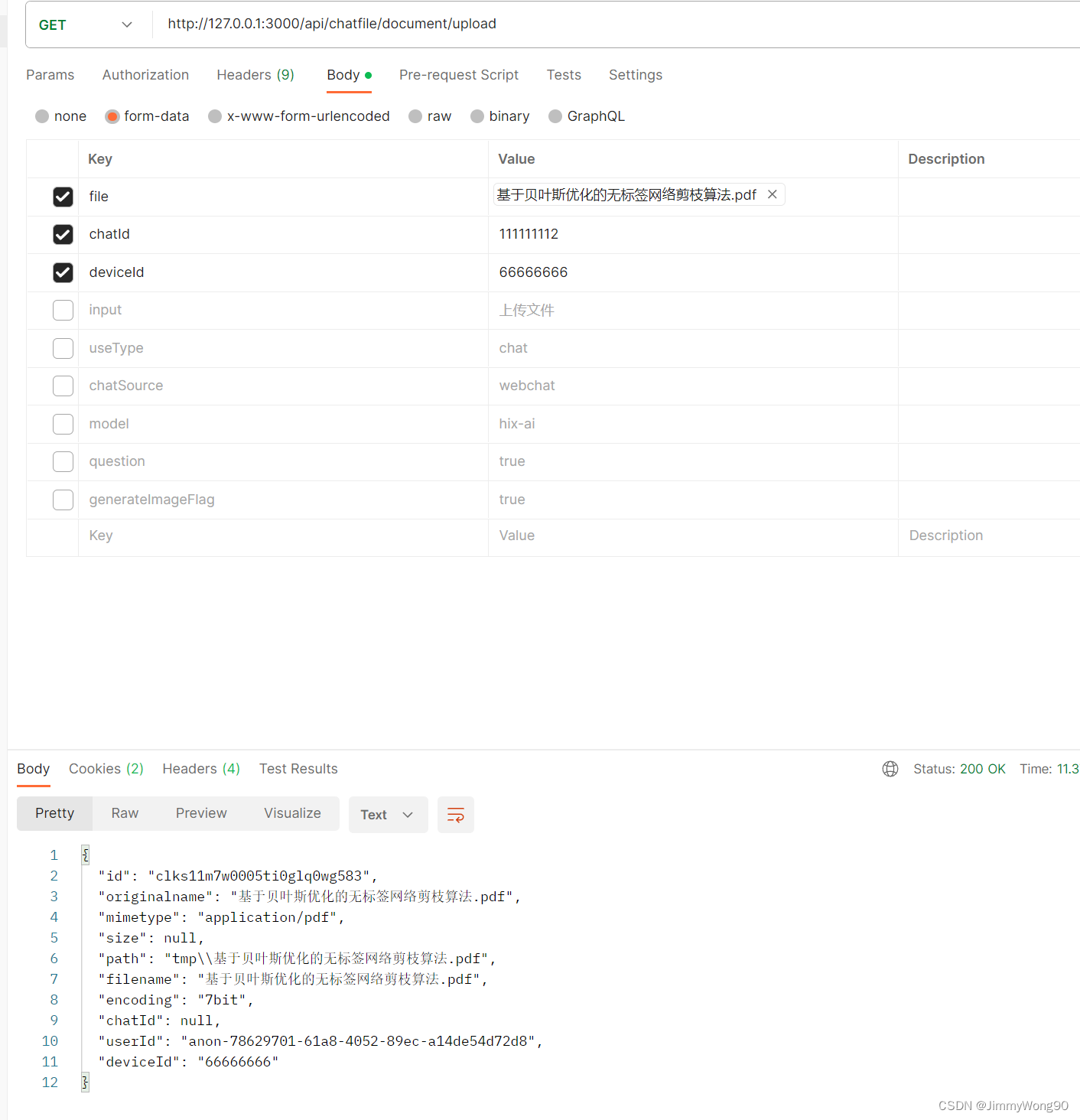
存在疑问:暂时是把文件保存在tmp文件夹,定时清理,是否使用云存储
根据不同的文件类型选取不同的文件加载器加载文件内容
switch (file.mimetype) {case 'application/pdf':loader = new PDFLoader(file.path)breakcase 'text/plain':loader = new TextLoader(file.path)breakcase 'application/msword':loader = new DocxLoader(file.path)breakcase 'application/vnd.ms-excel':case 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet':loader = new CSVLoader(file.path)breakcase 'application/json':loader = new JSONLoader(file.path)breakcase 'text/html':default:loader = new TextLoader(file.path)}存在疑问:我们通过后缀名还是mimetype来区分加载器,langchain使用的是后缀名
文本分割:
顾名思义,文本分割就是用来分割文本的。为什么需要分割文本?Prompt 会存在字符限制
比如我们将一份300页的 pdf 发给 openai api,让他进行总结,他肯定会报超过最大 Token 错。所以这里就需要使用文本分割器去分割我们 loader 进来的 Document。
主要代码:这里分块长度为1000,每次携带上下文20
const textSplitter = new RecursiveCharacterTextSplitter({chunkSize: 1000,chunkOverlap: 20,})
文本向量化
我们和文件进行交流的时候不可能每次都把全量文本都当成prompt传给Gpt ,所以需要进行文本向量化,文本向量化后就可以进行文本相关性查询,查出最符合的内容交与GPT进行相关性问答
建立一张上传文本表,往数据库插入一条上传信息,获取到id,用于向量查询的不同命名空间
表结构设计如下
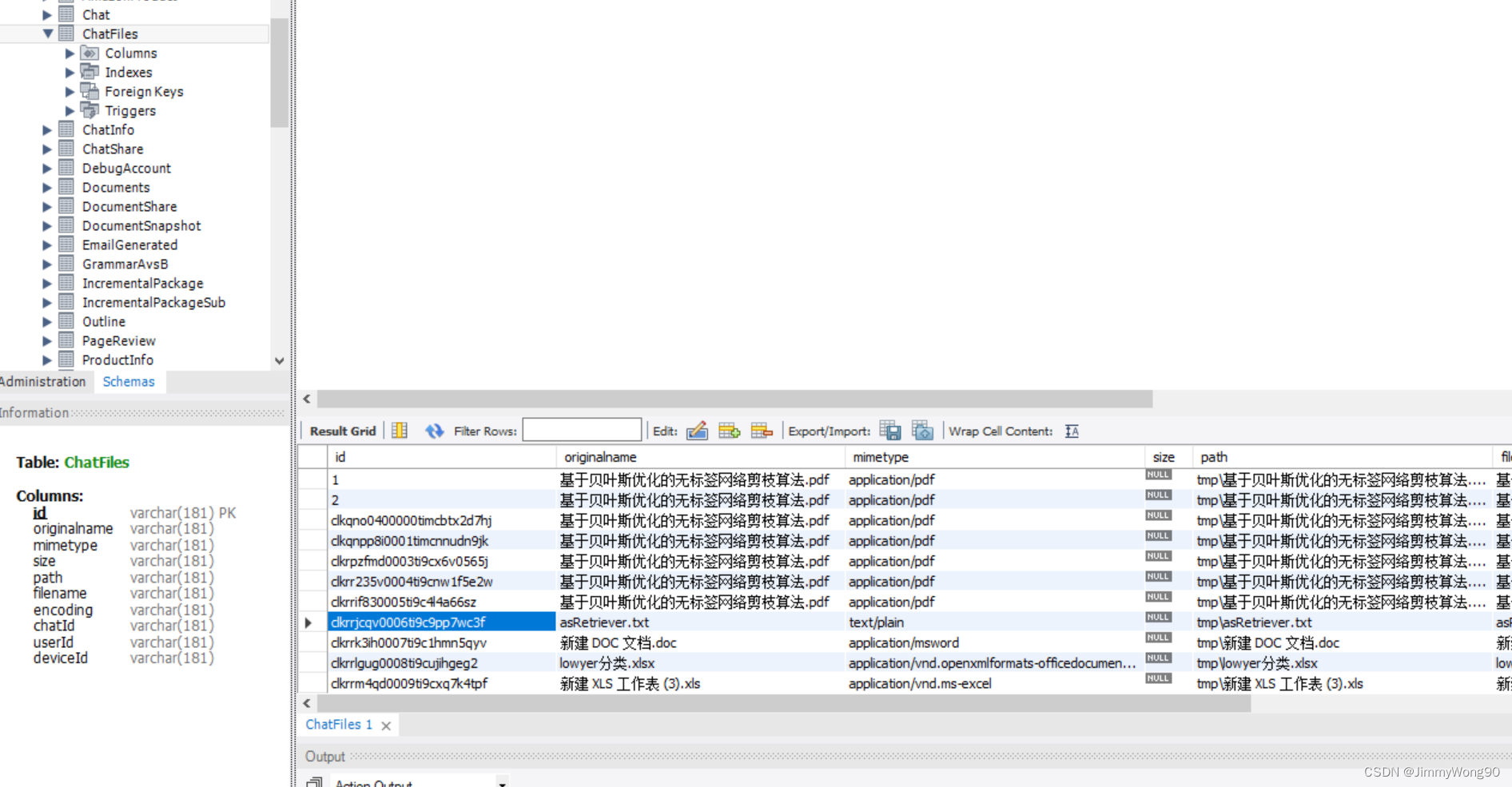
const data = await prisma.chatFiles.create({data: {originalname: file.originalname,mimetype: file.mimetype,path: file.path,filename: file.filename,encoding: file.encoding,userId,deviceId,},})
向量文本内容持久化
console.log('创建向量数据库,持久化')const store = await PineconeStore.fromDocuments(docs,new OpenAIEmbeddings(),{pineconeIndex,// namespace: `${userId}_${file.filename.replace('.pdf', '')}`,namespace: `${data.id}`,},)
我们需要把向量化的文本持久化,便于下次进行聊天或者连续性问答,通过后台文本表查询该次聊天向量文本内容,这里暂时使用个人的云向量库
文本聊天的流程
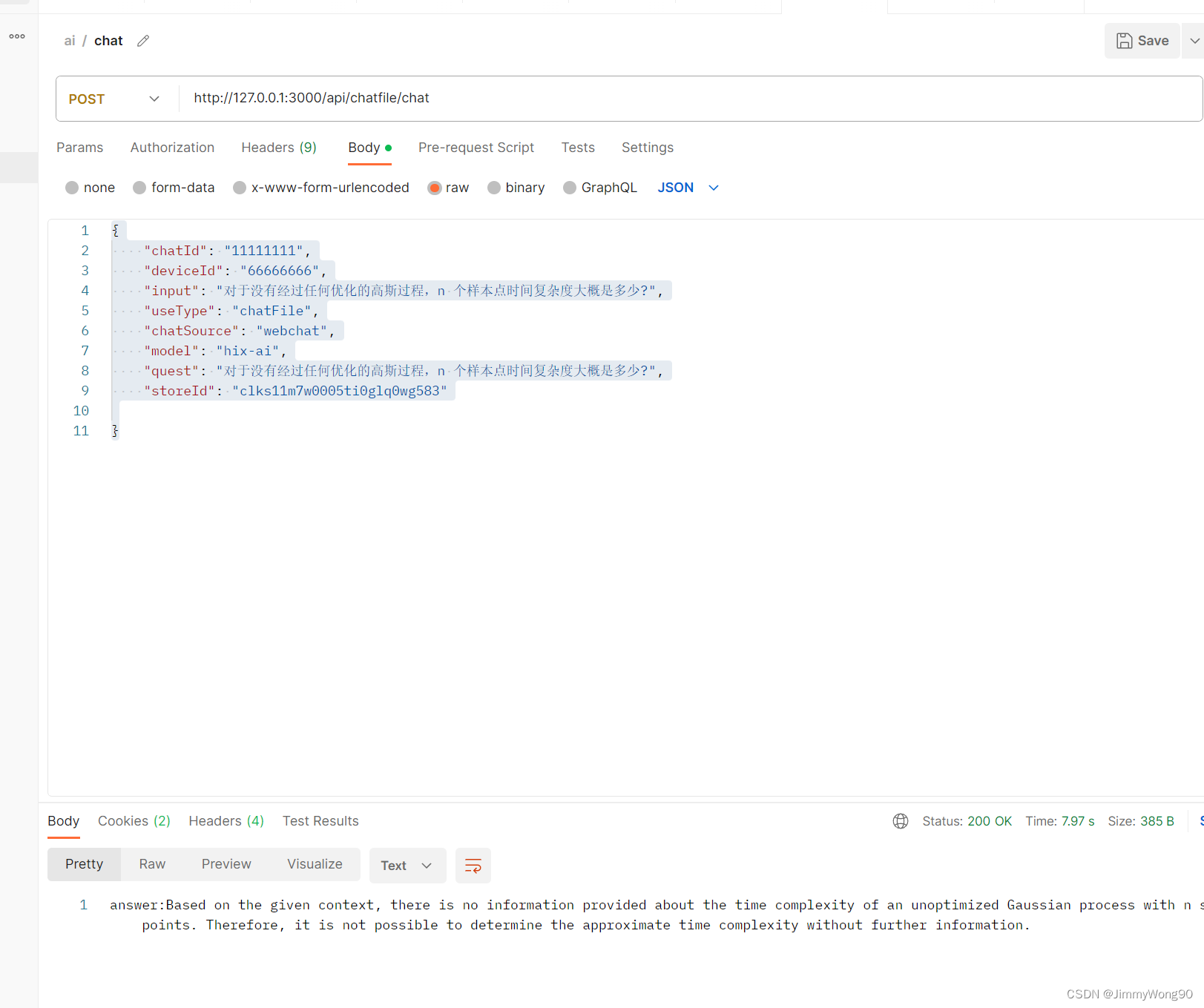
1. 需要传入后台保存的文本表对应id,便于寻找相应向量数据库
const store = await PineconeStore.fromExistingIndex(new OpenAIEmbeddings(), {pineconeIndex,namespace: storeId,})chatFiles(quest, functionName, res, callback, chatInfoId, store)
2.chatfile 的核心代码
// 使用retriever进行向量相似查询,找到相关数据const docs = await this.retriever.getRelevantDocuments(question);const inputs = { question, input_documents: docs };// 将数据交给gpt进行处理
文本总结的核心流程
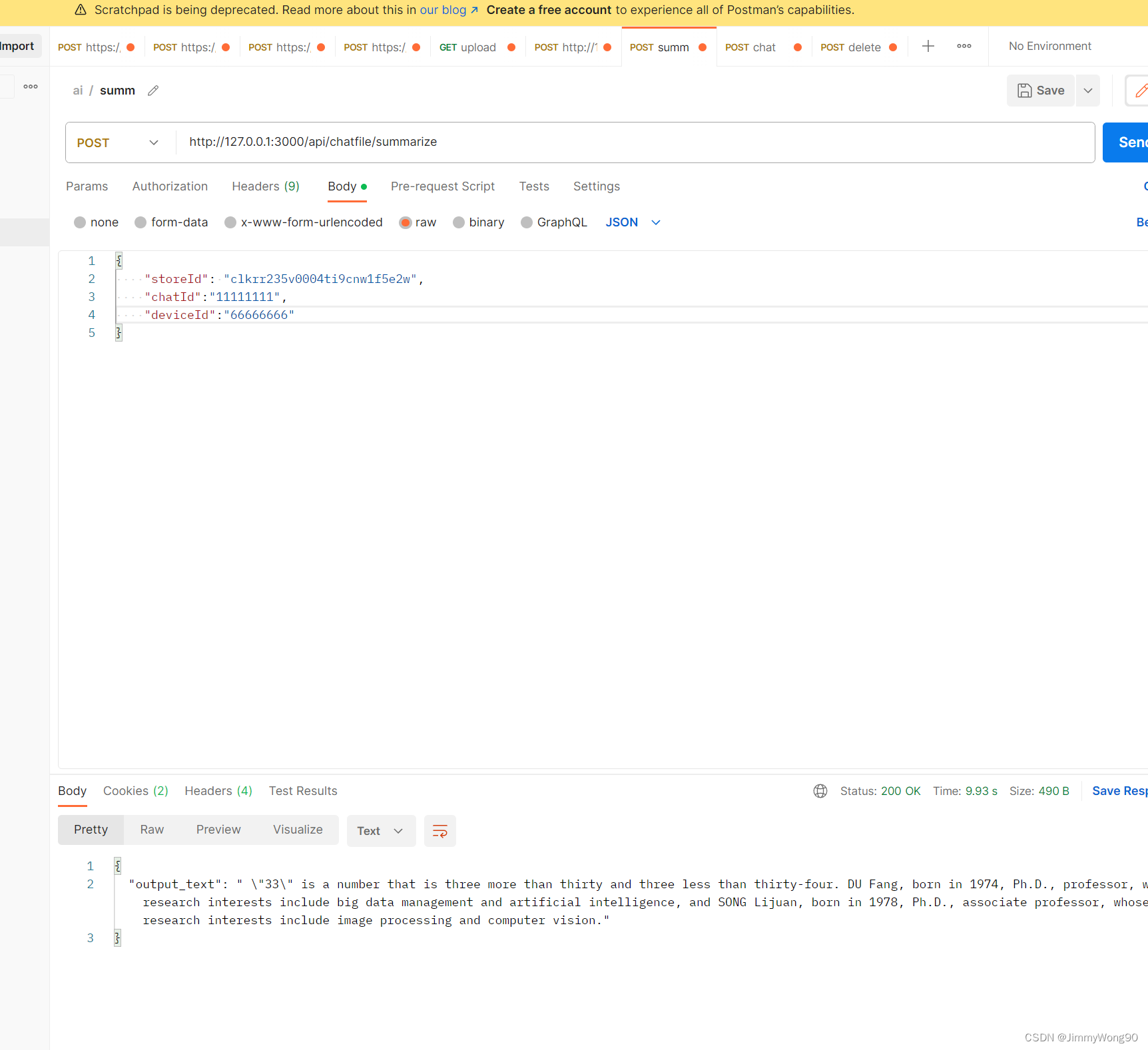
1. 需要传入后台保存的文本表对应id,便于寻找相应向量数据库
const store = await PineconeStore.fromExistingIndex(new OpenAIEmbeddings(), {pineconeIndex,namespace: storeId,})// 获取前N个文档进行总结,需要产品进行定义const docs = await store.asRetriever(3).getRelevantDocuments('')const chain = loadSummarizationChain(new OpenAI({ temperature: 0 }))const response = await chain.call({input_documents: docs.slice(0, 2),})
总结类型使用refine,链式总结,把前面的chunk总结内容带入prompt 进行总结,总结内容更精准
map_reduce 的话,分段总结然后进行合并,时间更快
需要设计一个删除文本相关的接口
const obj = await prisma.chatFiles.findFirst({ where: { id: storeId } })if (obj) {const obj = await prisma.chatFiles.delete({ where: { id: storeId } })obj && obj.path && fs.unlinkSync(obj.path)await pineconeClient.init({apiKey: process.env.PINECONE_API_KEY,environment: process.env.PINECONE_ENVIRONMENT,})const pineconeIndex = pineconeClient.Index('01')await pineconeIndex.delete1({ deleteAll: true, namespace: storeId })}